
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 구조분해할당
- 백준 #코딩테스트
- 유니티 #게임개발
- useEffect
- 코딩테스트
- typeScript
- 리액트
- axios
- TS
- 혼공머신
- js
- 백준
- 백준 #코딩테스트 #코테 #알고리즘
- 혼공단
- clipboardapi
- 머신러닝
- 에러해결방안
- Redux
- styledcomonents
- 혼공챌린지
- 타입스크립트
- 혼자공부하는머신러닝딥러닝
- CSS
- 딥러닝
- 초기값 설정하기
- error맛집
- reactmemo
- 알고리즘
- REACT
- 혼자공부하는머신러닝
Archives
- Today
- Total
좌충우돌 개발자의 길
10강 : 확률적 경사 하강법 본문
점진적 학습
- 이전에 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하기
확률적 경사 하강법
- 점진적 학습의 알고리즘
- 경사를 따라 내려가는 방법이라는 뜻으로 훈련세트에서 랜덤하게 하나의 샘플을 골라 가장 가파른 길을 찾아 내려오는 것을 확률적 경사 하강법이라고 한다.
IF) 다 내려오지 않았는데 모든 샘플을 다 썼다면?
- 다시 처음부터 시작하면 된다
- 훈련 세트에 모든 샘플을 다시 채워 넣고 다시 랜덤하게 하나의 샘플을 선택해 이어서 경사를 내려감
⇒ 에포크 : 확률적 경사 하강법에서 훈련 세트를 한 번 모두 사용하는 과정을 말함
에포크
- 확률적 경사 하강법에서 훈련 세트를 한 번 모두 사용하는 과정을 말함
- 일반적으로 경사 하강법은 수십, 수백 번 이상 에포크를 수행함
미니배치 경사 하강법
- 한개씩 말고 무작위로 몇개의 샘플을 선택해 경사를 따라 내려가기는 방식
배차 경사 하강법
- 극단적으로 한 번 경사로를 따라 이동하기 위해 전체 샘플을 사용하는 것
간략 정리
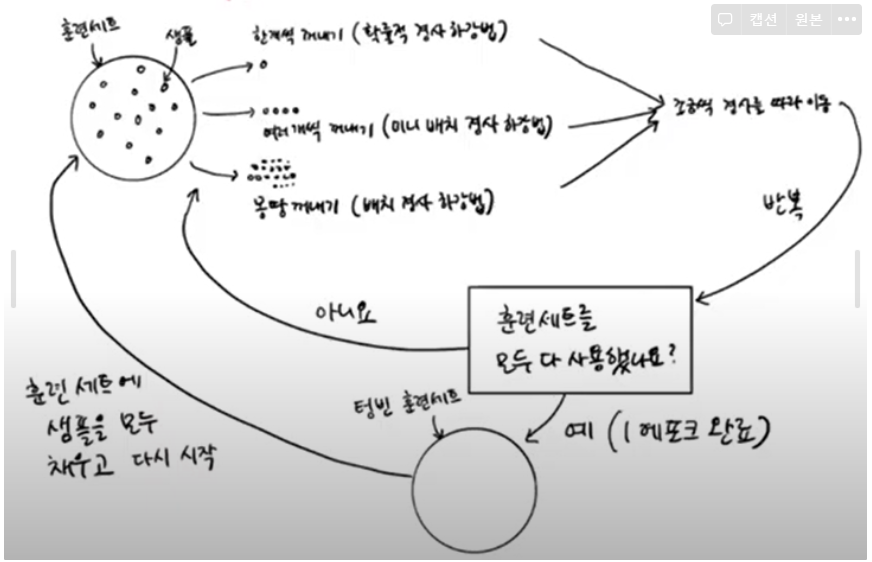
⇒ 이 방식으로 훈련 데이터가 모두 준비되어 있지 않고 매일매일 업데이트 되어도 학습을 계속 이어나갈 수 있다!
확률적 경사 하강법과 신경망 알고리즘
- 확률적 경사 하강법에 꼭 사용하는 알고리즘인 신경망 알고리즘
- 신경망 모델이 확률적 경사 하강법이나 미니배치 경사 하강법을 사용한다
손실함수
- 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지 측정하는 기준
- 손실 함수의 값이 작을수록 좋음
- 손실함수와 비용함수는 다른말이지만 엄격히 구분하지 않고 섞어 사용함
- 분류에서 손실은 명확함 → 정답을 못맞치는 것임
- 정확도가 듬성듬성(0 0.25 0.5 0.75 1)하면 경사 하강법을 이용해 조금씩 움직일 수 없다. ⇒ 산의 경사면은 확실히 연속적이어야함 (=손실함수는 미분이 가능해야함)
로지스틱 손실 함수 (=이진 크로스엔트로피 손실 함수)
- 예측이 1과 가까울수록 예측과 타깃의 곱의 음수는 점점 작아짐 (이진분류이용)
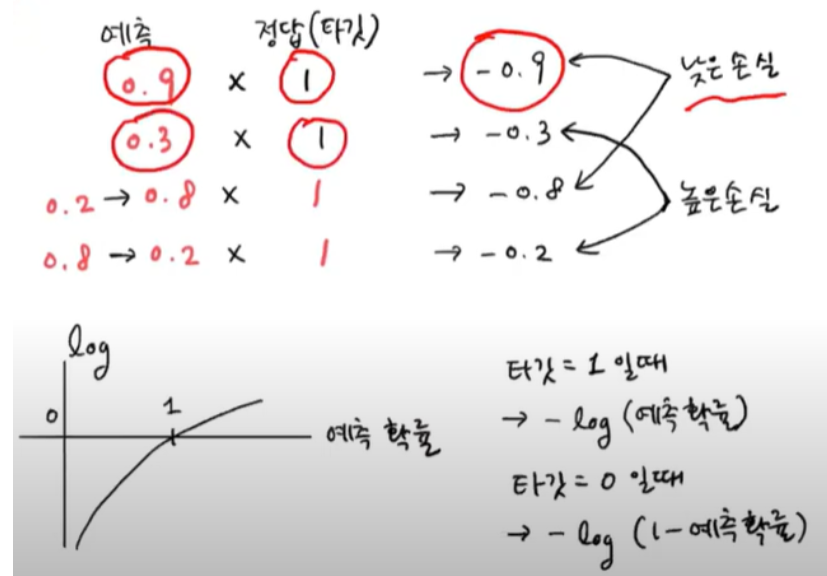
- 세번째, 네번째의 경우 음성클래스라 타깃이 0이므로 아무리 곱해도 0이 나오므로 1-0.2,1-0.8을 하여 양성클래스처럼 바꿔 계산함
두번째 그림
- 예측확률에 로그 함수를 적용하면 더 좋다
크로스엔토리피 손실 함수
- 다중 분류에서 사용하는 손실 함수
SGDClassifier
- 판다스 데이터 프레임 만들기
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')- Species 열을 제외한 나머지 5개 입력데이터 사용
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()- train_test_split() 함수를 사용해 훈련세트와 테스트세트로 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target =
train_test_split(fish_input, fish_target,random_state=42)- 훈련 세트와 테스트 세트의 특성을 표준화 전처리하기 (꼭 훈련 세트에서 학습한 통계값으로 테스트 세트도 변환해야함)
from sklearn.preprocessing import StandardScaler
ss = StandardSclaser()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)- SGDClassifier 클래스 가져오기
- loss = 손실 함수의 종류 지정 ⇒ log : 로지스틱 손실 함수 지정
- max_iter = 수행할 에포크 횟수 지정
sc = SGDClassifier(loss='log', max_iter = 10 , random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))결과값 : 0.773109243697479 // 0.775
⇒ 훈련 세트와 테스트 세트의 정확도가 낮음 → 반복횟수를 늘려주자 (ConvergenceWarning 경고가 뜨면 반복 횟수 늘리라는 신호)
- partial_fit() 메서드 사용
- SGDClassifier 객체를 다시 만들지 않고 훈련한 모델 sc를 추가로 더 훈련해주는 매서드
- 모델을 이어서 훈련할 때 사용
- fit() 메서드와 동일한 사용법을 가지지만 호출할때마다 1에포크씩 이어서 훈련 가능
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, trian_target))
print(sc.score(test_scaled, test_target))결과값 : 0.8151260504201681 // 0.825
⇒ 아까보다 정확도 상승했지만 더 훈련할 필요가 있다 → 그렇다면 얼마나 반복할지 기준이 무엇일까?
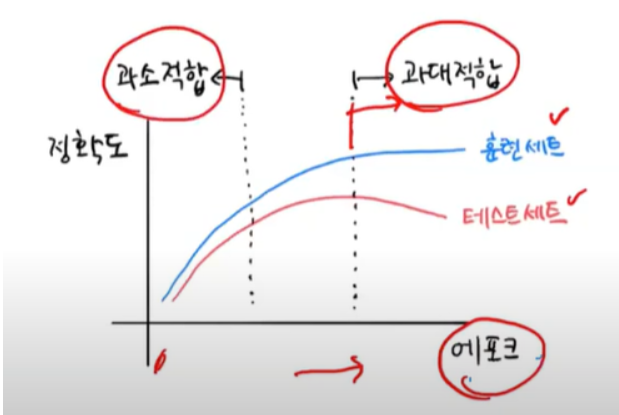
에포크와 과대/과소적합
- 에포크 횟수 너무 多 → 과대적합
- 에포크 횟수 너무 少 → 과소적합
- 조기 종료 : 과대적합이 시작하기 전에 훈련을 멈추는 것
- partial_fit() 매서드만 사용하기
- 훈련 세트에 있는 전체 클래스의 레이블을 partial_fit() 메서드에 전달해주기
- np.unique() 함수로 train_target에 있는 7개 생선의 목록 만들기
- 에포크마다 훈련 세트와 테스트 세트에 대한 점수를 기록하기 위해 2개의 리스트 준비
import numpy as np
sc = SGDClassifier(loss='log', random_state = 42)
train_score = []
test_score = []
classes = np.unique(train_target)
- 300번의 에포크 훈련하기
- 반복마다 훈련 세트와 테스트 세트의 점수를 계산해 train_scroe, test_score 리스트에 추가하기
for _ in range(0,300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
- 그래프 그리기
import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()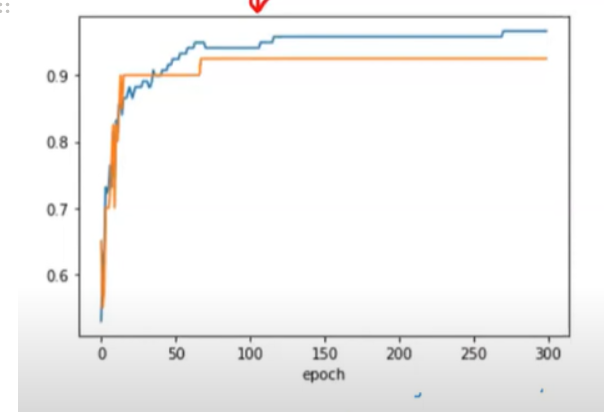
⇒ 백번째 에포크 이후에는 훈련 세트와 테스트 세트의 점수가 조금씩 벌어지고 있음
⇒ 에포크 초기에는 과소적합되어 훈련 세트와 테스트 세트의 점수가 낮음
⇒ 즉, 100번째 에포크가 적절한 반복횟수임
- SGDClassifier 의 반복횟수를 100에 맞추고 다시 훈련하기
sc = SGDClassifier(loss='log', max_iter = 100, to=None, random_state=42)
sc.fit(train_scaled,train_target)
print(sc.score(train_scaled, trian_target))
print(sc.score(test_scaled, test_target))결과값 : 0.973894534123 // 0.925
⇒ SGDClassifier 는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련안하고 자동으로 멈춤
⇒ tol : 향상될 최솟값 지정 (none으로 지정한 것은 자동으로 멈추지 않고 max_iter=100만큼 무조건 반복하도록 함)
loss 매개변수
- 기본값 : hinge
- 힌지 손실 : 서포트 백터 머신이라 불리는 또다른 머신러닝 알고리즘을 위한 손실 함수
- 서포트 벡터 머신이 널리 사용하는 머신런이 알고리즘 중 하나이다
- SGDClassifer가 여러 종류의 손실함수를 loss 매겨번수에 지정하여 다양한 머신러닝 알고리즘을 지원함
# 힌지 손실을 사용해 같은 반복 횟수 동안 모델을 훈련해보기
sc = SGDClassifier(loss="hinge', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, trian_target)
print(sc.score(train_scaled, trian_target))
print(sc.score(test_scaled, test_target))
#결과값
0.949535235652
0.925
'STUDYING > 머신러닝&딥러닝' 카테고리의 다른 글
| [WEEK4] 혼자서 공부하는 머신러닝 4주차 (0) | 2021.08.01 |
|---|---|
| [WEEK3] 혼자서 공부하는 머신러닝 + 딥러닝 3주차 (0) | 2021.07.24 |
| 9강 : 로지스틱 회귀 알아보기 (0) | 2021.07.24 |
| [WEEK2] 혼자서 공부하는 머신러닝 + 딥러닝 2주차 (0) | 2021.07.19 |
| 8강 : 특성 공학과 규제 (0) | 2021.07.18 |
'STUDYING/머신러닝&딥러닝' Related Articles
more



