
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 혼공단
- REACT
- typeScript
- styledcomonents
- Redux
- 딥러닝
- TS
- 코딩테스트
- 리액트
- 타입스크립트
- 초기값 설정하기
- reactmemo
- js
- 에러해결방안
- 구조분해할당
- error맛집
- 혼자공부하는머신러닝
- 알고리즘
- useEffect
- 혼공머신
- 백준 #코딩테스트
- axios
- 혼공챌린지
- clipboardapi
- 유니티 #게임개발
- 백준 #코딩테스트 #코테 #알고리즘
- 머신러닝
- 백준
- CSS
- 혼자공부하는머신러닝딥러닝
- Today
- Total
좌충우돌 개발자의 길
9강 : 로지스틱 회귀 알아보기 본문
데이터 준비하기
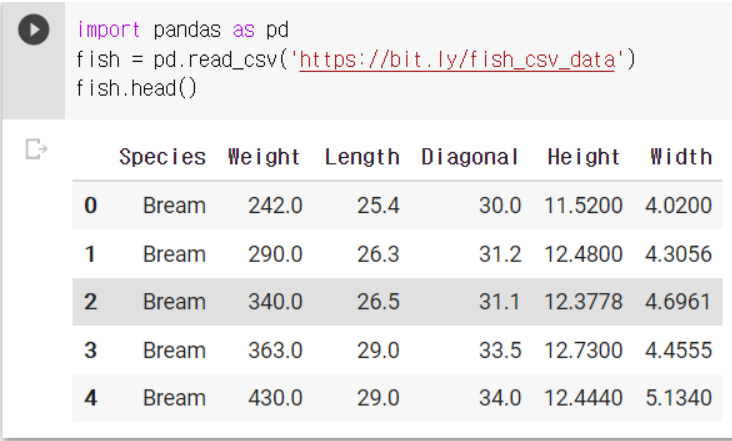
unique 함수 사용하기
- Species 열에서 고유한 값을 추출해보기 - unique 함수 사용

to_numpy()
- 데이터 프레임에서 여러 열을 선택하면 새로운 데이터프레임이 반환되는데 이를 to_numpy매서드로 넘파이 배열로 바꾸어 fish_input에 저장 (+ fish_target에 저장)
- 5개 행을 출력해봄

훈련세트와 테스트세트로 나누기

사이킷런의 StandardScaler 클래스를 사용해 훈련 세트와 테스트 세트를 표준화 전처리하기
- 훈련세트의 통계값으로 테스트 세트 변환하기

k-최근접 이웃 분류기의 확률 예측

- 다중 분류 : 타깃 데이터에 2개 이상의 클래스가 포함된 문제
- 이진분류와 모델을 만들고 훈련한느 방식은 동일함
- 사이킷런에선느 편리하게 문자열로 된 타깃값을 그대로 사용 가능
- → KNeighborsCalssfier에서 정렬된 타깃값은 classes_ 속성에 저장됨

처음 5개의 샘플의 타깃값을 예측하기
print(kn.predict(test_scaled[:5]))
predict_proba()
- 사이킷런의 분류 모델은 predict_proba() 매서드로 클래스별 확률값을 변환
- decimals 로 소수점 자리 몇까지 출력 가능

- 출력 순서 (네번째 샘플 예시)
→ 0 : 첫번째 클래스(Bream)에 대한 확률
→ 0 : 두번째 클래스(Parkki)에 대한 확률
→ 0.6667 : 세번째 클래스 Perch
→ **0 : 첫번째 클래스(Bream)**에 대한 확률
네번째 샘플의 최근접 이웃의 클래스 확인하기
- 앞서 만든 모델이 계산한 확률이 가장 가까운 이웃의 비율이 맞는지 확인하기

- 다섯번째 클래스인 Roach가 1개이고 세번재 클래스인 perch가 2개
- 다섯번재 클래스에 대한 확률은 1/3 = 0.3333이고 세번재 클레스에 대한 확률은 2/3=0.6667이므로 앞서 출력한 네번째 샘플의 클래스와 확률이 같다
⇒ But!! 3개의 최근접이웃을 사용하기 때문에 가능한확률은 0/3 1/3 2/3 3/3 이 전부이다. 더 나은 방법을 찾아보자
로지스틱 회귀
- 로지스틱 회귀는 이름은 회귀지만 분류 모델이다
- 이 알고리즘은 선형회귀와 동일하게 선형 방정식을 학습함
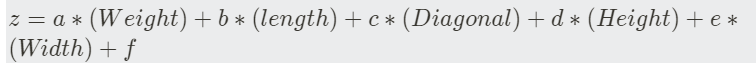
- a, b,c,d는 가중치 혹은 계수
- 확률이 되기 위해선 z는 0~1 사이 값이 되어야 하고 z가 아주 큰 음수일때 0이 되고 z가 아주 큰 양수일 때 1이 되도록 바꾸어야한다
- ⇒ 시그모이드 함수(==로지스틱 함수) 사용하기
- 0.5이면 음수로 판독
시그모이드 함수
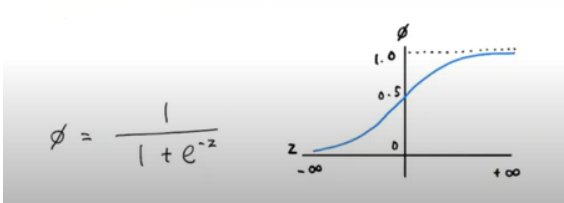
⇒ z가 어떤 값이 되더라도 결과값은 0~1 사이의 범위를 벗어날 수 없음
⇒ 0~1 사이 값을 0~100%까지 확률로 해석할 수 있음
넘파이를 활용하여 시그모이드 함수 그리기

→ 사이킷런에는 로지스틱 회귀모델인 LogisticRegression 클래스가 준비되어 있음
로지스틱 회귀로 이진분류 수행하기
- 불리언 인덱싱 : 넘파이 배열은 True, False값을 전달하여 행을 선택할 수 있음
- ex/ A와 C만 골라내면 첫번째와 세번재 원소만 True이고 나머지 원소는 모두 False인 배열을 전달하면 됨

도미와 빙어의 행만 골라내기

- train_target=='Bream' : train_target 배열에서 도미인 것은 True이고 그 외는 모두 False인 배열을 반환함
- 연산자 or을 사용하면 도미와 빙어에 대한 행만 골라낼 수 있음
로지스틱 회귀 모델 훈련해보기

훈련한 모델 사용해 train_bream_smelt에 있는 처음 5개 샘플 예측
print(lr.predict(train_bream_smelt[:5]))
predict_proba() 메서드 이용해 train_bream_smelt에 있는 처음 5개 샘플 확률 예측하기
print(lr.predict_proba(train_bream_smelt[:5]))
→ 첫번째 열 : 음성 클래스(0)에 대한 확률, 두번째 열 : 양성 클래스(1)에 대한 확률
Bream과 Smelt 중 어떤 것이 양성 클래스?
print(lr.classes_)
→ 빙어인 smelt가 양성클래스
Bream과 Smelt 중 어떤 것이 양성 클래스?
print(lr.coef_, lr.intercept_)
decision_function() 메서드로 z값 출력하기
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)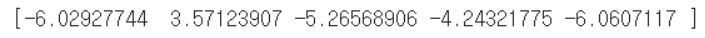
→ 이 z값을 시그모이드 함수에 통과시키면 확률 얻을 수 있음
⇒ np.exp() 함수를 사용해보자
np.exp() 함수로 확률 값 얻기
from scipy.special import expit
print(expit(decisions))
⇒ predict_proba() 메서드 출력의 두 번째 열의 값과 동일
⇒ 즉 decision_function() 메서드는 양성 클래스에 대한 z값 반환
요약
- predict_proba() : 음성클래스와 양성클래스에 대한 확률 출력하기
- decision_function() : 양성 클래스에 대한 z값을 계산
- coef_속성과 intercept_ 속성에는 로지스틱 모델일 학습한 선형 방정식의 계수가 들어가 있음
로지스틱 회귀로 다중 분류 수행하기
- LogisticRegression 클래스를 사용해 7개의 생선을 분류해보자
- max_iter 매개변수(얼마나 반복)의 기본값이 100인데 더 늘려서 1000으로 설정
- LogisticRegression에서 규제를 제어하는 매개변수는 C로 기본값은 1이고 작아질 수록 규제가 커짐 → 규제완화를 위해 20으로 늘림
- 다중 분류 몯레을 훈련하는 코드로 7개의 생선이 모두 들어있는 trian_scaled와 train_target을 사용함

⇒ 훈련세트와 테스트 세트에 대한 점수가 높고 과대적합이나 과소적합으로 치우치지 않음
테스트 세트의 처음 5개 샘플에 대한 예측 출력
print(lr.predict(test_scaled[:5]))
테스트 세트의 처음 5개 샘플에 대한 예측 확률 출력하기
- 소수점 네번째 자리에서 반올림

⇒ 5개에 대한 샘플이므로 5개의 행이 출력되고 7개 생선에 대한 확률 계산으로 7개의 열이 출력됨
첫번째 열의 84.1%는 (Perch)에 대한 확률인가?
- classes_ 속성에서 클래스 정보 확인하기
print(lr.classes_)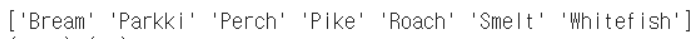
⇒ 맞음
다중 분류일 경우 선형 방정식은 어떤 모습일까?
- coef_와 intercept_의 크기를 출력해보기
print(lr.coef_.shpae, lr.intercept_shape)⇒ 결과 값 : (7, 5) (7, )
⇒ 5개의 특성을 사용하므로 coef_ 배열의 열은 5개, 행이 7인데 intercept도 7개인 것은 z를 7개나 계산했다는 의미
⇒즉, 다중 분류는 클래스마다 z값을 하나씩 계산함
⇒ 가장 높은 z값을 출력하는 클래스가 예측클래스가 됨
- 소프트맥스 함수를 사용해 7개의 z값을 확률로 변환함

decision_function() 으로 z1~z7까지 구하고 소프트맥스 함수를 이용해 확률로 바꾸기
- z1~z7까지 구하기
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2))
- 소프트맥스 함수를 이용해 확률로 바꾸기
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
- axis 매개변수는 소프트맥스를 계산할 축을 지정하고 각 샘플에 대해 소프트맥스를 계산한다. ( 지정안하면 배열 전체에 대해 소프트맥스를 계산함)
- proba 배열과 비교해보면 결과가 일치함 → 성공
'STUDYING > 머신러닝&딥러닝' 카테고리의 다른 글
| [WEEK3] 혼자서 공부하는 머신러닝 + 딥러닝 3주차 (0) | 2021.07.24 |
|---|---|
| 10강 : 확률적 경사 하강법 (0) | 2021.07.24 |
| [WEEK2] 혼자서 공부하는 머신러닝 + 딥러닝 2주차 (0) | 2021.07.19 |
| 8강 : 특성 공학과 규제 (0) | 2021.07.18 |
| 7강 : 선형회귀 (0) | 2021.07.18 |



