
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 코딩테스트
- 타입스크립트
- CSS
- 딥러닝
- 리액트
- 혼자공부하는머신러닝
- 백준 #코딩테스트 #코테 #알고리즘
- Redux
- 백준
- 유니티 #게임개발
- 에러해결방안
- axios
- 혼공챌린지
- js
- TS
- REACT
- 머신러닝
- useEffect
- clipboardapi
- 구조분해할당
- 초기값 설정하기
- error맛집
- 혼자공부하는머신러닝딥러닝
- 알고리즘
- styledcomonents
- reactmemo
- 백준 #코딩테스트
- 혼공머신
- 혼공단
- typeScript
Archives
- Today
- Total
좌충우돌 개발자의 길
6강 : k-최근접 이웃 회귀 본문
농어의 무게를 예측하라
- 회귀 : 임의의 숫자를 예측하는 것 (타깃==임의의 숫자 == 농어의 무게)
- 지도학습에 회귀와 분류가 있는 것
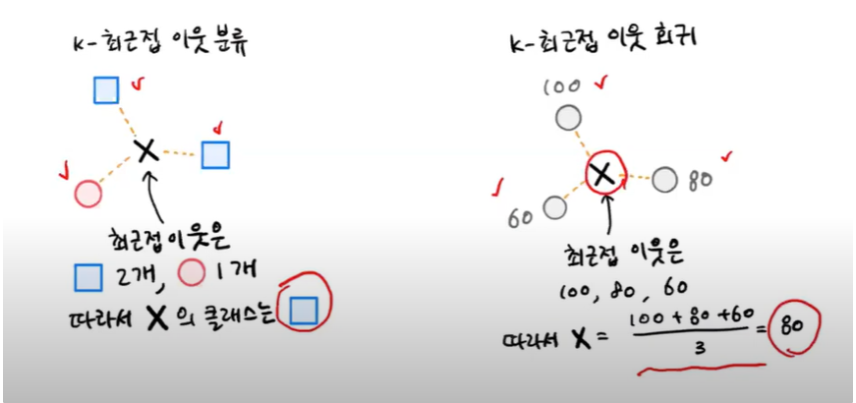
→ 분류 : 주변 이웃의 클래스를 보고 네모이다!
→ 회귀 : 주변 이웃의 타깃을 보고 평균 내서 구하기!
농어의 길이만 사용
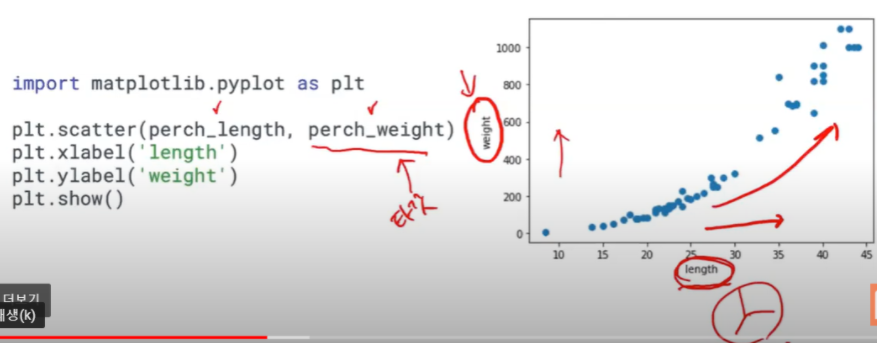
→ perch_weight가 타깃값
→ 분류일 때는 클래스(별, 네모, 마름모..)로 구별이 가능하기에 특성을 두개로 해도 괜찮
→ 회귀일 때는 분류처럼 구별하기 힘들어서(임의의 숫자로 구분하기에) 특성 1개, 타깃1개로 구분 (특성 : 길이, 타깃: 무게)
훈련 세트 준비하기

- stratify가 없는 이유 : stratify 매개변수(지정안하면 false라서 지정해줘야함)에 타깃값을 넣었는데 이유는 클래스별로 골고루 훈련세트랑 테스트 세트랑 나누라고 넣음 → 보통 회귀는 stratify 안쓰고 랜덤하게 섞어서 훈련세트와 테스트 세트로 나누는 것이 일반적
- reshape()
- perch_length가 1차원배열이기에, test_input과 train_input도 1차원 배열임
- 하지만 사이킷런에 사용할 훈련세트는 2차원 배열이어야한다!(지난 강의는 특성이 2개였기에 자동으로 2차원 배열이었다)
- train_target과 test_target은 1차원이라서 바꿀 필요 x
- [1,2,3 ] 의 크기는 (3, ) 이고 이를 2차원 배열로 만들기 위해 억지로 하나의 열을 추가해야한다 —> [[1],[2],[3]]로 만들면 크기가 (3,1)이 됨
- ⇒ 즉, 배열을 나타내는 방식만 달라지고 원소의 개수는 동일
- ⇒ 이렇게 만들려면 reshape() 사용해야함
-
# (-1, 1)크기로 만들어주겠다 train_input = train_input.reshape(-1, 1)- → train_input과 test_input을 2차원 배열로 바꾸자, train_input의 크기는 (42, )임
- → 2차원 배열로 바꾸면 (42, 1)로 해야함 ⇒ train_input.reshape(42,1)
- → BUT 넘파이는 자동으로 배열의 크기를 지정하는 기능 제공 : -1
- ⇒ train_input.reshape(-1,1) 하면 크기에 -1 지정하면 나머지 원소 개수를 모두 채우라는 의미로 첫번째 크기를 나머지 원소 개수로 채우고 두번째 크기(열이 하나이고)를 1로 하려할 때 이렇게 사용
-
- [1,2,3 ] 의 크기는 (3, ) 이고 이를 2차원 배열로 만들기 위해 억지로 하나의 열을 추가해야한다 —> [[1],[2],[3]]로 만들면 크기가 (3,1)이 됨
회귀 모델 훈련
# 이미 제공되어있는 회귀관련 라이브러리가 있음
from sklearn.neghbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
# 결정계수로 값이 도출 (<-> 분류 : 정확도로 값이 도출)
knr.score(test_input, test_target)
0.9982656565
------------------------
# 평균 절대값 오차 방법으로 앞 코드와 다른 방법으로 구해볼 수 있다
from sklearn.metrics import mean_absolute_error
# test_input으로 예측한 값
test_prediction = knr.predict(test_input)
# 테스트 세트에 대한 평균 절댓값 오차를 계산
# test_target과 test_prediction의 차이만 나는 절대값을 평균내서
mae = mean_absolute_error(test_target, test_prediction)
print(mae)
# 평균적으로 19g 정도 타깃값과 다르다
19.1571424546- 결정계수 : 타깃값 (==test_target의 타깃, 예츨, 평균)

→ 예측이 평균에 가까워지면 1이 되기에 결정계수는 0에 가까워짐
⇒ 예측이 타깃에 아주 가까워지만 1에 가까운 값이 나옴(1에 가까워야 좋은 값)
과대적합과 과소적합
훈련세트와 테스트세트 각각 결정계수 구하면 보통 훈련세트가 테스트 세트보다 더 높은 결과값이 나와야 함
→ 과소적합 : 훈련 세트가 테스트 세트보다 결정계수가 낮은 경우
→ 과대적합 : 훈련 세트가 테스트 세트보다 결정계수가 높지만, 각각 0.9와 0.6으로 너무 차이가 나서 테스트 세트가 형편없는 기능을 하는 경우
- 과대적합, 과소적합 문제 해결 하기
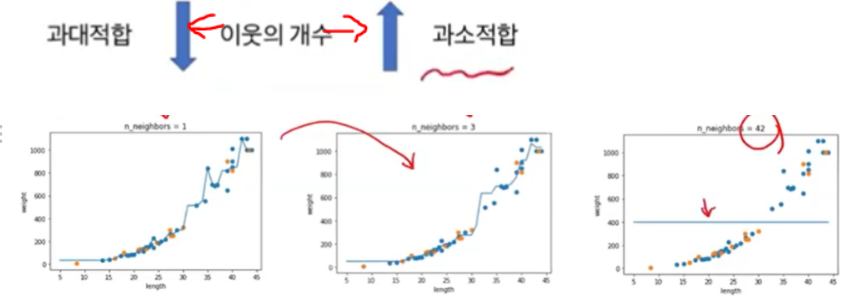
→ 세번째 그래프는 너무 많이 이웃값을 올려서 극단적으로 1개만 예측하는 결과가 나와버림

→ 기본 5개의 이웃들을 3개로 줄여 계산해본 결과, 옳은 결과가 나왔다.
'STUDYING > 머신러닝&딥러닝' 카테고리의 다른 글
| 8강 : 특성 공학과 규제 (0) | 2021.07.18 |
|---|---|
| 7강 : 선형회귀 (0) | 2021.07.18 |
| 5강 : 데이터 전처리 (0) | 2021.07.14 |
| 4강 : 훈련 세트와 테스트 세트 (0) | 2021.07.14 |
| 3강 : 마켓과 머신러닝 (0) | 2021.07.14 |
'STUDYING/머신러닝&딥러닝' Related Articles
more



